── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Upon doing some googling about text analysis, I found here: https://cran.r-project.org/web/packages/tidytext/vignettes/tidytext.html, an example using tidytext to do an analysis of the Jane Austen novels. This inspired me to do one on Twilight, which I had been debating in my personal life lately so it felt right.
I was able to download a pdf of the first twilight book, which I moved to my project folder as per the advice of ChatGPT when I couldn’t figure out how to open a pdf in R.
So the first things I had to do to it to work with it were to get it in a format I was comfortable with and clean it up.
##Extracting text from the pdf - using pdftools, which Google recommended to use - generates a character vector, each element is one page of text from the bookfile.exists("tw1.pdf")
[1] TRUE
tw1_raw <-pdf_text("tw1.pdf")str(tw1_raw)
chr [1:537] "" ...
##Now I need to turn it into a data frame - so now we have a column of pages and a column of text on that pagetw1_df <-tibble(page =seq_along(tw1_raw), text = tw1_raw)head(tw1_df)
# A tibble: 6 × 2
page text
<int> <chr>
1 1 ""
2 2 "I'd never given much thought to how I would die —\nthough I'd had reas…
3 3 " FIRST SIGHT\n\nMy mother drove me to the airport w…
4 4 "My mom looks like me, except with short hair and\nlaugh lines. I felt …
5 5 "permanence. He'd already gotten me registered for\nhigh school and was…
6 6 "\"I found a good car for you, really cheap,\" he\nannounced when we we…
##Google says that the tidytext format is "one-token-per-row", which would be in this case making it one word per row. tw1_tidy <- tw1_df %>%unnest_tokens(word, text)head(tw1_tidy)
# A tibble: 6 × 2
page word
<int> <chr>
1 2 i'd
2 2 never
3 2 given
4 2 much
5 2 thought
6 2 to
##The Jane Austen example taught me what "stop words" are -words like "to", "and", "of", "the", etc that I don't care to involve in my analysis. Getting rid of those, and getting rid of numbers. data("stop_words")tw1_tidy_clean <- tw1_tidy %>%filter(!str_detect(word, "^[0-9]+$")) %>%anti_join(stop_words, by ="word")head(tw1_tidy_clean)
# A tibble: 6 × 2
page word
<int> <chr>
1 2 die
2 2 reason
3 2 months
4 2 imagined
5 2 stared
6 2 breathing
Now to do the actual text analysis.
##How many times each word shows uptw1_word_count <- tw1_tidy_clean %>%count(word, sort =TRUE)head(tw1_word_count)
# A tibble: 6 × 2
word n
<chr> <int>
1 twilight 540
2 meyer 536
3 stephanie 536
4 eyes 497
5 edward 377
6 voice 339
## Okay, so this showed me that "twilight", "stepanie", and "meyer", aka the title and name of author are the most common. So I'll get rid of those. tw1_word_count <- tw1_word_count %>%filter(word !="twilight", word !="meyer", word !="stephanie")head(tw1_word_count)
# A tibble: 6 × 2
word n
<chr> <int>
1 eyes 497
2 edward 377
3 voice 339
4 looked 266
5 time 212
6 bella 208
So top 5 words are “eyes”, “edward”, “voice”, “looked”, and “time”. Which I think does make sense because the book is written from the point of view of Bella, falling in love with Edward, and she does focus a lot during the book on how angelic she finds his eyes and voice, and she does spend considerable time worrying about time, and aging, since he is a vampire does not age.
One criticism of Twilight is the age difference between Edward and Bella, with people feeling like he sinisterly influence her, forced her, manipulated her, scared her, etc into being with him (which if you read it, does not happen). To explore this, I wanted to see how Bella was describing her feelings in the book to see if she was feeling negatively in any way. Google told me a sentiment analysis is a common approach for a text analysis, so I proceeded with that.
##Using the Bing sentiment lexicon, look at the sentiment/connotation of each word. tw1_sentiment <- tw1_tidy_clean %>%inner_join(get_sentiments("bing"), by ="word")##Count between negative and positive, which is more prevalent. tw1_sentiment %>%count(sentiment)
# A tibble: 2 × 2
sentiment n
<chr> <int>
1 negative 4293
2 positive 2399
I found it a little interesting that a love story would have 4293 words with negative sentiment and only 2399 words with positive sentiment. BUT it is a vampire novel, an outside vampire is actively trying to kill Bella at the end of the book. And at the beginning, she was apprehensive about leaving her mom and moving in with her dad. The love story was mostly in the middle. So I wondered if I could see if the vibe was changing throughout the story and how.
##In order to get in a sort of "over time" format, I reformatted by page instead of by word. tw1_sentiment_page <- tw1_sentiment %>%count(page, sentiment) head(tw1_sentiment_page)
##Now I can see how mnany negatives and positives per page, but I want to know if each page is overall negative or positive. tw1_sentiment_score <- tw1_sentiment_page %>%mutate(value =if_else(sentiment =="positive", n, -n)) %>%group_by(page) %>%summarise(score =sum(value), .groups ="drop")head(tw1_sentiment_score)
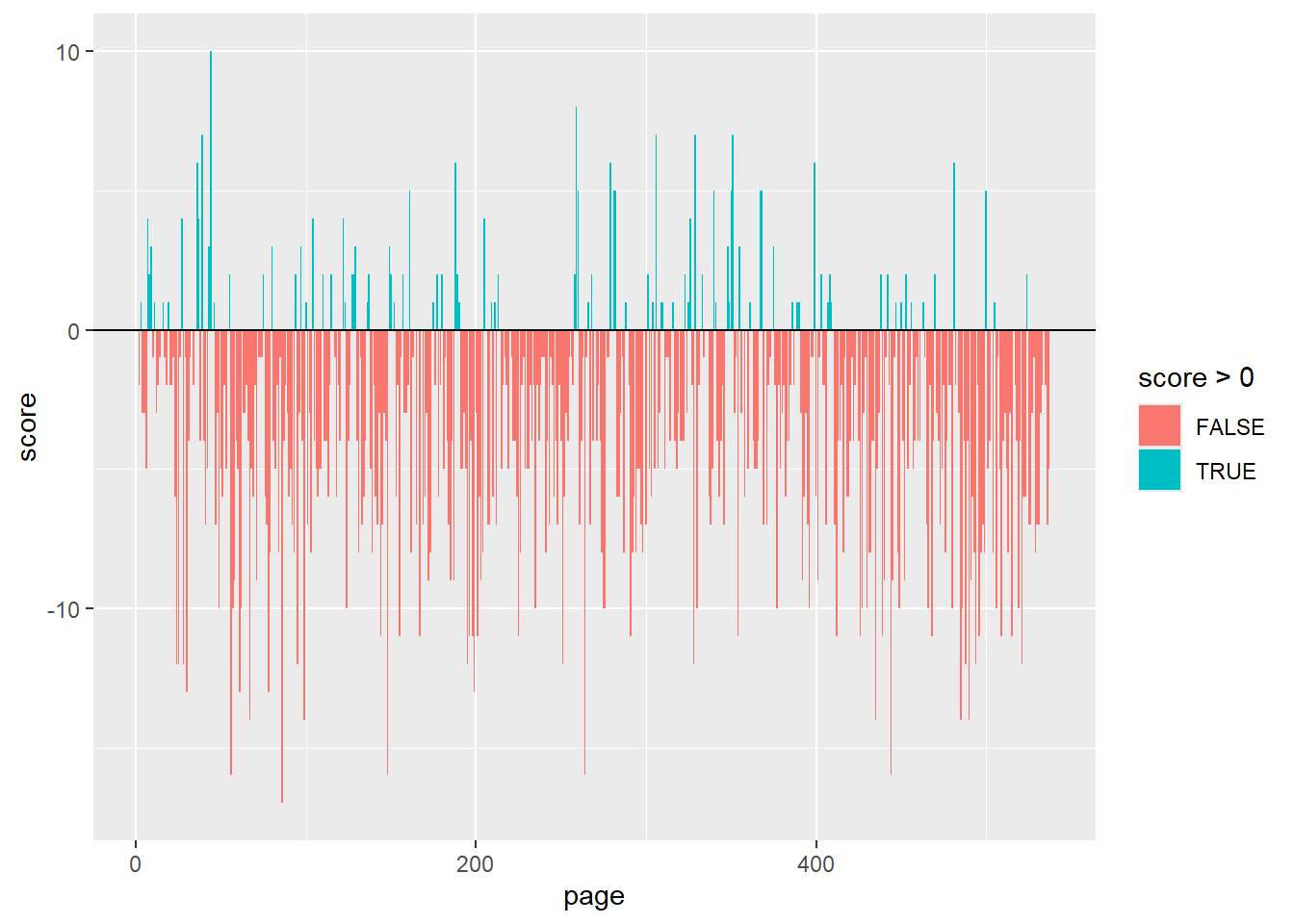
##To visualize how sentiment changed over time, I made a bar graph. ggplot(tw1_sentiment_score, aes(x = page, y = score, fill = score >0)) +geom_col() +geom_hline(yintercept =0)
Oof, okay. Well, looking at this chart, I cannot discern any pattern of more negative at the start and end, but more positive in the middle. It looks mostly negative throughout. Reading it I really remember more the love story, but maybe that’s because I’m a fan. I’ll have to read it again.